yanzx@nnnu.edu.cn
欢迎访问南宁师范大学心理学课程数字化资源库!
yanzx@nnnu.edu.cn
##练习数据
data(mpg)
?psych
library(psych)
###describe
describe(mpg)
#四分位距
describe(mpg,IQR=T)
#四分位数
describe(mpg,quant=c(.25,.75) )
#感兴趣的部分统计
mpg.x <- c("cyl","cty")
describe(mpg[mpg.x],data = mpg)
#or
describe(mpg[c("cyl","cty")],data = mpg)
#部分展示数据
describeData(mpg)
#显示变量及数量
describeFast(mpg)
print(describeFast(mpg),short=FALSE)
##调整展示的小数位数、有效位数
des.mpg <- describe(mpg)
des.mpg
print(des.mpg,digits=3)
print(des.mpg, signif=3)
###describe by 分组描述统计
describeBy(mpg,group = mpg$drv)
describeBy(mpg,group = mpg$drv,mat = T)
describeBy(mpg,group =list( mpg$drv,mpg$class))
#formula model:~
describeBy(mpg~drv,mat = T)
describeBy(mpg~drv+class)
#感兴趣
describeBy(mpg$cty,group = mpg$drv,mat = T)
describeBy(mpg$cty,group = mpg$drv,mat = T,digits = 3)
des <- describeBy(mpg$cty,group = mpg$drv,mat = T,digits = 3)
describeBy(hwy+cty~drv,data = mpg)
describeBy(hwy+cty~drv+year,data = mpg)
###stats by 组内与组之间的统计数据
data(sat.act)
statsBy(sat.act,"education")
print(sat.act,short=F)
#两个分组变量
statsBy(sat.act,c("gender","education"))
#查看概率值、平均数、标准差
sat.stats <- statsBy(sat.act,"education")
sat.stats$pbg
# 辅助工具lowerMat(看value) 显示矩阵的下三角形 digits:3
lowerMat(sat.stats$pbg)
print(sat.stats$sd)
round(sat.stats$sd,digits = 3)
lowerMat(round(sat.stats$sd,digits = 3))
###寻找并绘制多层数据的各种可靠性/泛化系数 mlArrange
#有结构的数据集 分组展示(person:组,time:x轴,item:分值y轴)
#mlr multilevel.reliability
data(sat.act)
multilevel.reliability(sat.act,grp="education",Time="gender",items=
c("ACT","SATV","SATQ"),plot=T)
#例子
?structure
shrout <- structure(list(Person = c(1L, 2L, 3L, 4L, 5L, 1L, 2L, 3L, 4L,
5L, 1L, 2L, 3L, 4L, 5L, 1L, 2L, 3L, 4L, 5L),
Time = c(1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 3L,
3L, 3L, 3L, 3L,4L, 4L, 4L,4L, 4L),
Item1 = c(2L, 3L, 6L, 3L, 7L, 3L, 5L, 6L, 3L, 8L, 4L,
4L, 7L, 5L,6L, 1L, 5L, 8L, 8L, 6L),
Item2 = c(3L, 4L, 6L, 4L, 8L, 3L,7L, 7L, 5L, 8L, 2L,
6L, 8L, 6L,7L, 3L, 9L, 9L, 7L, 8L),
Item3 = c(6L, 4L, 5L, 3L, 7L, 4L, 7L, 8L, 9L, 9L,
5L, 7L, 9L,7L, 8L, 4L, 7L, 9L, 9L, 6L)),
Names = c("Person", "Time", "Item1", "Item2", "Item3"),
class = "data.frame",row.names = c(1:20))
shrout
mg1 <- multilevel.reliability(shrout,grp="Person",Time="Time",
items=c("Item1","Item2","Item3"),plot=TRUE)
mg1
mlr(mg1$long,grp="id",Time ="time",items="items", values="values",long = T)
#long:数据是宽格式(默认)还是长格式
multilevel.reliability(shrout, grp="Person",Time="Time",
items = c("Item1","Item2","Item3"),
alpha=TRUE,icc=FALSE,
aov=TRUE,lmer=FALSE,lme = TRUE,long=FALSE,
values=NA,na.action="na.omit",plot=TRUE,
main="Lattice Plot by subjects over time2")
###headTail 显示数据帧、矩阵或文本对象的第一行和最后n行的快速方法(后几个已淘汰)
headTail(mpg, top=4,bottom=4,from=1,to=NULL, digits=2, hlength = 4, tlength =4,
ellipsis=TRUE)
###pairs.panels 数据矩阵的散点图、直方图和相关性
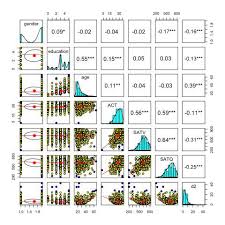
data(sat.act)
pairs.panels(sat.act)
pairs.panels(sat.act,show.points=FALSE,stars=T)
###correlation 找出矩阵或数据框架元素之间的相关性、样本量和概率值
corr.test(sat.act)
sat.corr <- corr.test(sat.act)
lowerMat(sat.corr$r)
#对感兴趣变量做相关
a <- c("ACT","SATV","SATQ")
corr.test(sat.act[a])
sat.a.corr <- corr.test(sat.act[a])
#or
corr.p(sat.a.corr$r,700,adjust="holm",alpha=.05,minlength=5,ci=TRUE)
#看置信区间
print(corr.p(sat.a.corr$r,700,adjust="holm",alpha=.05,minlength=5,ci=TRUE),
short = F)
#标记相关显著(去掉引号)
print(sat.a.corr$stars,quote=F)
#其他相关
kendall.r <- corr.test(sat.act[a], method="kendall", normal=FALSE)
kendall.r
##correlation plot:对相关关系或因素矩阵做图
corPlot(sat.act)
corPlot(sat.act,cex = T,MAR = T)
corPlot(sat.act,main = "satplot",stars = F)
corPlot(sat.act,main = "satplot",stars = T)
#以相关分析中的相关矩阵作图
corPlot(sat.corr$r,numbers = T,diag = F,stars = T,pval=T,sort=T,zlim=c(0,1),
main = "correlation plot with sort")
#红色表示小于 .5
#pval:按其值对数字进行缩放,根据削减的值对它们进行分类
corPlot(sat.corr$r)
corPlot(sat.corr$r,cex = T,MAR = T)
#选择相关矩阵中的某几个变量做图
sat.a.corr$r
corPlot(sat.a.corr$r, zlim=c(-1,1),main="sat",select=c(1,3),cex=T)
corPlot(sat.a.corr$r, zlim=c(0,1),main="sat",select=c(1,3))
corPlot(sat.a.corr$r, zlim=c(-1,1),main="sat",select=c(1,3),cex=T)
#置信区间
corPlotUpperLowerCi(R=sat.corr,numbers=TRUE,cuts=c(.001,.01,.05),select=NULL,
main="Upper and lower confidence intervals of correlations",
adjust=FALSE,cex=T)
### multi.hist {psych}:多个直方图与密度和正常匹配在一个页面
multi.hist(sat.act,freq = T,bcol = "green",
dcol = c("red","blue"),dlty=c("dashed","dotted"))
histBy(sat.act,"SATQ","gender",main="Histograms by gender")
histBy(SATQ~ gender, data=sat.act)
#偏度,峰值,Mardia's test
skew(sat.act, na.rm = TRUE,type=3)
kurtosi(sat.act, na.rm = TRUE,type=3)
mardia(sat.act,na.rm = TRUE,plot=TRUE)
#Q-Q plot: 观察值与期望值的重合情况
#几何平均数
geometric.mean(sat.act,na.rm=TRUE)
#调和平均数
harmonic.mean(sat.act,na.rm=TRUE,zero=TRUE)
###绘制均值和置信区间
#error.bars.
error.bars(sat.act[a])
error.bars(sat.act[a],sd=T,bars=T)
error.bars(sat.act[a],sd=T,add = T,bars=T, within=T)
boxplot(sat.act[a],notch=TRUE,main="Notched boxplot with error bars")
#50%置信区间 alpha
error.bars(sat.act[a],alpha=.5,
main="50 percent confidence limits")
##结合条形图和箱线图
?stripchart
stripchart(sat.act[a],vertical=TRUE,method="jitter",jitter=.1,pch=19,
main="Stripchart with 95 percent confidence limits")
#add T/F
boxplot(sat.act[a],add=T)
error.bars(sat.act[a],add=TRUE,arrow.len=.2)
#分组显示不同变量的情况:error.bars.by
error.bars.by( SATV + SATQ ~ gender,data=sat.act,v.lab=cs(male,female))
error.bars.by(SATV + SATQ ~ education + gender, data =sat.act)
#条形图bar
error.bars.by(SATV + SATQ ~ education,data=sat.act,bars=T,xlab="Education",
main="95 percent confidence limits of Sat V and Sat Q",
ylim=c(0,800), v.labels=c("SATV","SATQ"),
colors=c("red","blue","green","black","white","orange") )
#error.crosses
des <- describe(sat.act)
#c:选取变量
x <- des[c(5,6),]
y<- des[c(5,6),]
error.crosses(x,y,xlab=rownames(x),ylab=rownames(y))
#···统计性数据
g1.stats <- data.frame(n=c(10,20,30),mean=c(10,12,18),se=c(2,3,5))
g2.stats <- data.frame(n=c(15,20,25),mean=c(6,14,15),se =c(1,2,3))
error.crosses(g1.stats,g2.stats)
###查找插值样本中位数、四分位数或特定分位数interpolated sample median
#中位数
interp.median(g1.stats, w = 1,na.rm=TRUE)
data(attitude)
interp.median(sat.act, w = 1,na.rm=TRUE)
#四分位数
interp.quartiles(sat.act,w=1,na.rm=TRUE)
interp.quantiles(sat.act, q = .5, w = 1,na.rm=TRUE)
interp.boxplot(sat.act,w=1,na.rm=TRUE)
#插值计算
#order排序
sat.order <- sat.act$ACT[order(sat.act$ACT)]
interp.values(sat.order)
barplot(sat.order,xlab="ordinal position",ylab="value")
#qplot: quick plot,ggplot2
interp.qplot.by(sat.act$ACT,sat.act$education,ylab="act"
,xlab="edu")
v1 <- c(1,1,2,2,2,3,3,3,3,4,5,1,1,1,2,2,3,3,3,3,4,5,1,1,1,2,2,3,3,3,3,4,2)
v2<- c(1,2,3,3,3,3,4,4,4,4,4,1,2,3,3,3,3,4,4,4,4,5,1,5,3,3,3,3,4,4,4,4,4)
v1 <- v1[order(v1)]
v2 <- v2[order(v2)]
interp.v1 <- interp.values(v1)
interp.v2<- interp.values(v2)
interp.v1
interp.v2
barplot(v1,space=0,xlab="ordinal position",ylab="value")